
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- fork
- exec
- ascii_easy
- dfs
- samsung research
- pwnable.kr
- Brute Force
- 알고리즘
- paging
- 시뮬레이션
- 삼성기출
- 완전탐색
- 백준
- 구현
- 스케줄링
- segmentation
- Memory Management
- 삼성리서치
- 데드락
- 가상메모리
- Deadlock
- 프로세스
- 백트래킹
- 컴공복전
- higunnew
- BFS
- 김건우
- BOJ
- 운영체제
- 동기화문제
- Today
- Total
gunnew의 잡설
4강. 스레드(Thread) 본문
드디어 스레드(Thread)와 프로세스(Process)의 차이를 구분할 수 있다! 운영체제 학습자의 숙원을 조금은 해소할 수 있게 된다. 결론부터 말하자면 스레드는 프로세스 내부에서의 CPU 수행 단위를 뜻한다. 이 말은 도대체 무슨 말일까? 이를 이해하기 위해서는 프로세스가 어떻게 관리되는지 상기할 필요가 있다.
프로그램을 실행하게 되면 프로세스가 생성된다. 프로세스가 생성되면 별도의 주소 공간이 할당되며 그 주소 공간에는 code, data, stack 영역이 만들어지고, OS kernel이 PCB(Process Control Block)를 만들어 해당 프로세스의 정보들을 저장한다. (PCB는 지난 3강에 걸쳐 설명하였다.)
만약 내가 거의 같은 일 혹은 비슷한 일들을 하는 프로그램을 여러 개 실행하고 싶다고 가정하자. 현재 우리가 할 수 있는 일은 당연히 프로세스를 그만큼 생성하는 것이다. 예를 들어 여러 묶음의 행렬을 곱하는 프로그램을 실행하고 싶다면, 그 개수만큼 프로세스를 생성하면 해결될 것이다. 그러나 이렇게 하는 건 조금 바보 같은 일이다. 어차피 비슷한 일들을 하는데 굳이 프로세스를 달리해야 하나? 그냥 한 프로세스 내부에서 무언가 조금만 바꿔주면 되지 않을까? 하는 생각을 할 수 있다.
여기서 스레드(Thread)가 등장한다. 스레드는 프로세스를 새로이 생성하지 않는다. 프로세스가 CPU를 점유하는 방법을 응용했다고 볼 수 있다. 프로세스는 PCB로 관리되는데 PCB에는 현재 프로세스가 어떤 코드를 실행하는지를 담고 있는 Program Counter, 당장에 필요로 하는 register set 등을 여러 개 만드는 것이다. 이해가 가지 않는다면 다음 <그림 1>을 살펴보자.
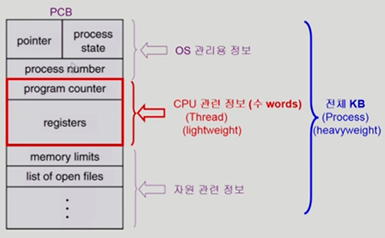
Program counter와 registers를 주목하자. 이것들은 CPU 내부에 있는 것들이다. 이것을 프로세스를 만들지 않고 여러 개의 일을 동시에 할 수 있게 만드는 스레드를 생성하면 다음과 같을 것이다. <그림 2>를 살펴보자.
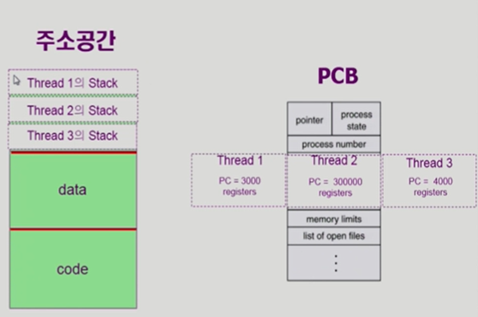
위와 같이 프로세스 내부에서 CPU 상태에 대한 정보를 담는 부분을 여러 개 만들어 놓으면 된다. 여기서 주의할 점은 스레드마다 stack 영역을 구분한다는 것이다. 스레드는 어찌 되었든 서로 다른 작업을 하는 작은 프로세스이기 때문에 stack을 공유하게 되면 함수 호출과 같은 작업을 할 때 서로 뒤엉키게 될 것이다. 따라서 stack은 스레드마다 구분한다는 사실을 잊지 말자.
스레드의 장점 |
이렇게 스레드를 만들면 어떤 장점이 있을까?
첫 번째로 높은 응답성(high resposivness)을 기대할 수 있다. 예를 들어 웹 페이지를 읽어 들이는 프로세스가 실행된다고 하자. 이것 또한 I/O 작업이기 때문에 읽어 오는 동안에는 blocked 상태가 될 것이다. 그렇게 되면 우리는 답답함을 느끼게 될 것이다. 해당 페이지를 읽어 오기 전까지는 해당 웹 페이지의 빈 화면만 바라보고 있어야 할 것이기 때문이다. 이러한 문제를 해결하기 위해 스레드를 사용할 수 있다. 만약 그림을 읽어 들이는 스레드, 텍스트를 읽어 들이는 스레드를 따로 둔다면 그림을 읽어 오는데 많은 시간이 걸리기 때문에 그림을 읽어 들이는 동안 텍스트라도 먼저 화면에 띄우는 작업을 해 준다면 사용자 입장에서는 프로세스가 진행되고 있다는 느낌을 받으며 높은 응답성을 달성할 수 있게 될 것이다.
두 번째로 자원 공유를 통해 자원을 절약할 수 있게 된다. 같은 일을 하는 프로세스를 여러 개 만드는 것은 각 프로세스의 주소 공간을 전부 메모리에 할당해야 하기 때문에 메모리 낭비가 심해진다. 만약 웹 브라우저를 여러 개 띄우거나 한글 파일을 여러 개 띄울 때 그 개수만큼 프로세스를 만든다면 엄청난 메모리 낭비가 일어날 것이다. 이를 해결하기 위해 스레드를 생성한다면, 한 프로세스 내에서 code와 data를 공유하며 stack 또한 스레드마다 나누어 쓰기 때문에 자원을 아주 compact 하게 사용할 수 있게 될 것이다.
세 번째로 프로세스 실행 속도의 향상을 통해 경제성을 달성할 수 있다. 프로세스를 새로이 만드는 것은 큰 overhead를 갖는다. 지난 강에서도 언급했듯이 프로세스를 생성하면 context switch가 일어날 때 cache memory flush와 같은 작업들을 해 주어야 하기 때문이다. 반면 스레드 간의 switch overhead는 프로세스의 그것보다 훨씬 작다. 쉽게 풀어 쓴다면 프로세스를 생성하는 것은 밥상을 새로이 하나 차리는 것이고 스레드를 만드는 것은 숟가락만 하나 얹는 것에 불과하다. 스레드는 어차피 하나의 프로세스이기 때문에 동일한 주소 공간을 공유하기 때문이다. 유닉스 계열의 Solaris 운영체제는 프로세스를 만드는 것의 overhead가 스레드를 만드는 것의 overhead보다 30배가 크고, context switch는 스레드보다 프로세스가 5배의 overhead를 갖는다고 알려져 있다.
여기까지는 싱글 코어(CPU가 1개인 컴퓨터)에서도 활용 가능한 스레드의 장점이다. 네 번째로는 Multiprocessor architecture에서의 병렬성을 활용하여 효율성을 극대화 할 수 있다. GPU를 통한 CUDA 프로그래밍과 같은 프로젝트를 해 본 사람이라면 코어의 병렬성이 작업 효율과 실행 시간을 얼마나 단축시키는지 느껴봤을 것이다. 가령 1000*1000 행렬의 곱셈을 진행할 때, GPU를 통해 코어를 병렬로 처리하여 계산한다면 단일 스레드를 이용하는 것보다 수 십 배에서 수 백 배의 속도 향상을 가져온다는 것을 확인할 수 있다.
추가적으로 스레드의 단점은 없냐고 물어볼 수 있는데, 스레드의 단점은 없다. 있다면 프로그래머가 관리하기 까다롭다는 것이다. 그 외에는 단점이 전혀 없다고 평가받는다.

스레드의 구현 방법(Simple Introduction) |
스레드를 구현하는 방법에는 크게 두 가지가 있다. 운영체제 커널에 의해 지원받는 스레드, 혹은 라이브러리에 의해 지원받는 스레드로 구현하는 것이다. 전자를 커널 스레드(Kernel Thread), 후자를 유저 스레드(User Thread)라고 부른다. 커널 스레드는 스레드가 여러 개 있다는 사실을 운영체제 커널이 알고 있으며, 하나의 스레드에서 다른 스레드로 CPU의 제어권이 넘어가는 것도 커널이 CPU 스케줄링을 하듯 스케줄링하도록 구현되는 것이다. 반면에 유저 스레드는 커널의 지원을 받지 않으며, 프로세스 내에 스레드가 여러 개 있다는 사실을 운영체제는 알지 못하고 사용자 프로그램이 스스로 라이브러리의 지원을 받아 스레드를 관리하게 되는 것을 뜻한다. 그렇기 때문에 약간의 구현 상 제약이 존재하긴 하나 본 강의에서는 이 정도로만 소개하고 마친다.

'Operating System' 카테고리의 다른 글
| 5-2강. 프로세스와 관련한 시스템 콜 (2) | 2020.01.24 |
|---|---|
| 5-1강. 프로세스 관리(Process Management) (0) | 2020.01.23 |
| 3-2강. 프로세스(Cont'd) (0) | 2020.01.21 |
| 3-1강. 프로세스 (0) | 2020.01.21 |
| 2강. 프로그램의 실행 (0) | 2020.01.21 |



