
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 백트래킹
- 스케줄링
- BFS
- exec
- Deadlock
- 삼성기출
- pwnable.kr
- paging
- Brute Force
- 백준
- 동기화문제
- 삼성리서치
- ascii_easy
- 알고리즘
- segmentation
- 프로세스
- 운영체제
- 가상메모리
- higunnew
- 김건우
- fork
- 데드락
- Memory Management
- dfs
- 시뮬레이션
- 구현
- 완전탐색
- BOJ
- samsung research
- 컴공복전
- Today
- Total
gunnew의 잡설
6-3강. CPU 스케줄링 알고리즘(Cont'd) 본문
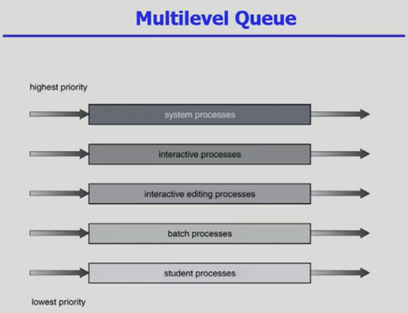
Multi-level Queue |
지금까지는 하나의 큐에 줄을 서는 것에 대해 이야기 했지만, 이번에 소개할 스케줄링 방법은 여러 큐를 통해 스케줄링하는 것이다. 이때 큐를 여러 갈래로 분류하는데 첫 번째로 Foreground queue이고 두 번째로 Background queue가 있다. Foreground queue에는 Interactive한 job들이 줄을 서고 Background queue에는 batch job – no human interaction job들이 줄을 선다.
Multi-level Queue 스케줄링에서는 큐 내부에 프로세스 우선순위가 아니라 큐의 우선순위를 결정한다. 즉, ‘큐에 대한 스케줄링’이 필요하다는 것을 의미한다.
1. 첫 번째 방법으로 Foreground queue의 우선순위를 극단적으로 높여서 CPU로 하여금 foreground queue가 비지 않는 이상 background queue가 CPU를 점유하지 못하게 통제할 수도 있는 것이다. 이것을 Fixed priority scheduling이라고 한다. 다만 이 경우 background job의 경우 SRTF에서 나타났던 문제와 비슷하게 starvation의 문제가 발생할 수 있다.
2. 두 번째로는 각 큐에 적절한 가중치를 주어서, 예를 들어 80%는 foreground job에 할당하고 20%는 background job에 스케줄링하는 것이다. 이 방법을 Time slice scheduling이라고 한다.
추가적으로 각 큐는 독립적인 스케줄링 알고리즘을 적용한다. 지난 시간에 스케줄링 알고리즘에 대해서 설명할 때 특히 interactive job들은 RR 스케줄링에서 가장 높은 효용성(high responsiveness)을 기대할 수 있다고 말했다. 반면 CPU bound job들은 문맥 교환의 overhead가 적은 것이 좋으므로 한 번에 처리할 수 있는 만큼을 모두 처리하는 것이 좋을 것이다. 따라서 foreground queue에는 RR 스케줄링을 적용하며 background job에는 FCFS 스케줄링을 적용한다. 다만 Multi-level Queue에서는 큐 간의 프로세스 이동, 그러니까 쉽게 말해 프로세스의 신분 이동을 금지한다.
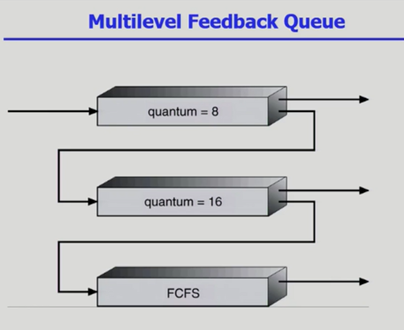
Multilevel Feedback queue |
방금 전 Multi-level Queue와 마찬가지로 여러 큐가 존재하는데 위와는 달리 신분 이동이 가능하다. 프로세스가 다른 큐로 이동하는 것이 가능하다는 것이다. Aging을 이 방식으로 구현 가능하기 때문에 starvation problem을 해결할 수 있다. 아무튼 Multilevel-feedback-queue도 큐가 여러 개이며 이렇게 큐를 멀티 레벨로 나누어야 하기 때문에 나누는 데에 필요한 여러 파라미터가 있다.
1. 큐의 수
2. 각 큐의 스케줄링 알고리즘
3. 프로세스를 상위 큐로 보내는 기준
4. 프로세스를 하위 큐로 보내는 기준
5. 프로세스가 CPU를 사용하려고 할 때 들어갈 큐를 결정하는 기준이 있다.
다음 예시는 Multilevel feedback queue의 구현 중 한 예시이다.
첫 번째 큐에는 할당 시간이 8인 프로세스들의 큐이다. 8 time unit이 지났을 때 CPU burst time이 남아있지 않다면 상관없지만, 만약 남아있다면 어떻게 될까? 다음 우선순위를 갖는 할당 시간 16인 프로세스들의 큐로 신분이 내려간다. 만약 16 time unit동안 지났음에도 CPU burst time이 남아있다면 FCFS 스케줄링을 사용하는 큐로 신분이 다시 하락하게 된다. 다만 여기서는 위의 파라미터 중 3번 프로세스를 상위 큐로 보내는 기준이 존재하지 않는 예시일 뿐이며 Multilevel feedback queue가 반드시 이렇게 구현되어야 하는 것은 아니다.

특수한 경우의 CPU 스케줄링 |
* Multi-Processor Scheduling (CPU가 여러 개인 환경)
1. CPU들이 모두 Homogeneous processor인 경우
Queue에 한 줄로 세워놓고 프로세서가 알아서 꺼내갈 수 있게 하는 경우가 있다. 그러나 반드시 특정한 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 좀 더 복잡해진다.
2. Load sharing (Load Balancing)
여러 CPU가 골고루 일을 하도록 하게 함. 즉 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘이 필요하다. 각 CPU마다 별개의 큐를 두는 방법 vs 공동 큐를 사용하며 CPU가 일할 수 있을 때 프로세스를 꺼내가는 방법이 있다. (화장실 각 칸마다 vs 한 줄 서기)
3. Symmetric Multiprocessing(SMP)
모든 프로세스가 대등하게 일을 하기 때문에 각 프로세스가 알아서 스케줄링을 하도록 결정한다. 예를 들어 큰 행렬의 곱셈과 같은 일을 할 때이다.
4. Asymmertric Multiprocessing
CPU 여러 개중에 한 개의 CPU가 대장 CPU가 되어서 데이터의 접근과 공유를 책임지고 나머지 프로세서는 그것을 따르는 스케줄링이 효과적인 경우가 있다.
* Real-Time Scheduling
우리가 일반적으로 쓰는 컴퓨터는 Real-time이 아니다. Real-time job은 주어진 deadline이 있고 반드시 이 시간 안에 처리가 되어야 하는 것을 말한다. 그런 상황에서의 스케줄링을 말한다. 이전에 했던 time-sharing OS에서 처럼 프로세스를 최대한 빠르게 처리해야 하는 문제가 아니다.
- Hard real-time systems
정해진 시간 안에 반드시 끝내도록 해야 하기 때문에 프로세스들의 load와 deadline과 같은 정보를 가지고 deadline을 어기지 않도록 CPU의 용량과 같은 것들을 미리 맞춰 놓아야 한다. 따라서 대개 Hard real-time은 그때그때 on-line으로 하는 것이 아니고 off-line으로 미리 스케줄링을 해놓고 그것대로 시스템이 따라가게 하는 경우가 많다. 지금까지 배웠던 time-sharing OS에서는 on-line으로 스케줄링을 했던 것이다.
- Soft real-time systems
데드라인을 어기면 안되긴 하지만 어겼을 때 큰일 나는 건 아니고 작은 불편 정도가 있다. 동영상을 스트리밍 하는 경우 초당 24 frames를 출력해 주어야 하는데 이걸 못하면 동영상이 끊기는 정도이며 큰일 나는 것은 아니다. 그래서 그냥 일반 컴퓨터에서 돌리게 된다. 그때 발생할 수 있는 문제들을 해결하기 위해 우선순위를 다른 프로세스보다 높여줘서 최대한 끊기지 않게 하는 것이 중요하다.
Thread Scheduling |
- Local Scheduling (User thread)
Thread의 구현 방법에 두 가지가 있다고 했다. User thread라고 해서 운영체제는 스레드의 존재를 모르고 사용자 프로세스가 내부에 스레드를 여러 개 두는 것이다. 이 경우는 운영체제 있는 CPU 스케줄러가 어느 스레드에게 CPU를 주겠다고 할 수는 없다. 그래서 그냥 스레드 여러 개인 프로세스에게 CPU를 주면 그 프로세스가 내부적으로 thread library에 의해 어떤 스레드를 스케줄 할지 결정한다.
- Global Scheduling (Kernel thread)
Thread의 구현 방법 두 번째는 Kernel thread이다. 이것은 운영체제가 thread의 존재를 아는 것이다. 그래서 아예 CPU 스케줄러가 어떤 스레드에 CPU를 줄지 직접 결정하는 형태이다.
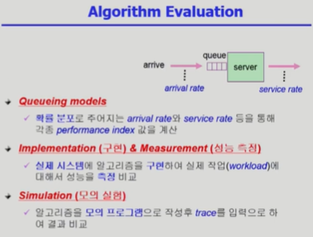
알고리즘 평가 방법 |
1. Queueing models
서버가 있어서 요청을 처리하는데 요청들이 큐에 쌓여 있다가 처리가 되면 빠져 나가는 모델이다. 본 강의의 주제인 CPU 스케줄링에 있어서 서버는 CPU이며, CPU를 쓰고자 하는 요청들이 큐에 도착하는데 도착률(얼마나 빠른 빈도로 CPU를 쓰겠다고 요청하는가)이 확률 분포로 주어지며, 처리율(단위 시간당 얼마나 일을 하는지)도 확률 분포로 주어졌을 때 Throughput, waiting time과 같은 performance index들을 계산한다.
2. Implementation(구현) & Measurement(성능 측정)
실제 시스템에 알고리즘을 구현하여 실제 작업에 대해서 성능을 측정한다. 리눅스의 스케줄링 소스 코드를 수정하여 컴파일한 후 실행하는 방법이 있다.
3. Simulation(모의 실험)
2번이 너무 어렵기 때문에(리눅스에서 소스 코드를 변경하고 실행해도 잘못하면 시스템이 그냥 죽어 버림) 그 대안으로 알고리즘을 모의 프로그램으로 작성 후 trace(주어진 작업)를 입력으로 하여 결과를 비교하는 것이다.
본 글들은 이화여대 반효경 교수님 2014학년도 1학기 운영체제 강의를 기반으로 작성됩니다.
링크 : http://www.kocw.net/home/search/kemView.do?kemId=1046323
'Operating System' 카테고리의 다른 글
| 7-2강. 동기화 문제 (0) | 2020.02.04 |
|---|---|
| 7-1강. 프로세스 동기화(Process Synchronization) (0) | 2020.01.30 |
| 6-2강. CPU 스케줄링 알고리즘 (1) | 2020.01.26 |
| 6-1강. CPU 스케줄링 (0) | 2020.01.24 |
| 5-3강. 프로세스 간의 협력 (0) | 2020.01.24 |



