
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- higunnew
- 알고리즘
- 스케줄링
- 구현
- 프로세스
- 김건우
- dfs
- paging
- 동기화문제
- 백트래킹
- 삼성기출
- fork
- BOJ
- 컴공복전
- Brute Force
- 완전탐색
- BFS
- samsung research
- exec
- 삼성리서치
- 가상메모리
- 운영체제
- 시뮬레이션
- segmentation
- Deadlock
- pwnable.kr
- Memory Management
- ascii_easy
- 데드락
- 백준
- Today
- Total
gunnew의 잡설
7-1강. 프로세스 동기화(Process Synchronization) 본문
프로세스 동기화를 설명하기에 앞서 컴퓨터 내부에서 연산이 이루어지면서 데이터에 접근하는 것이 어떻게 일어나는지 살펴보자. 다음 그림은 데이터의 접근이 일어나는 양상을 그림으로 나타낸 것이다.
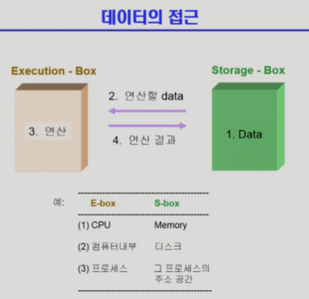
Race Condition(경쟁 상태에서 발생하는 문제, Concurrent access) |
연산을 할 때는 항상 무언가를 읽어 들이고 그 결과를 내보내는 작업이 필요하다. 이때 같은 데이터를 한 곳이 아니라 여러 곳에서 읽어서 연산을 할 때 문제가 발생할 수 있다. 즉, 연산 주체가 둘 이상일 때 하나의 데이터를 가지고 접근하는 경우 문제가 발생할 수 있다. 다음 예시를 살펴보자. 여기서는 본래 count를 하나 증가시키고 나서 count를 감소시켜 값의 변화를 없게 하려고 한다. 그런데 만약 count의 값을 왼쪽 박스가 먼저 읽어서 증가시키려고 한다고 하자. 이때 아직 왼쪽 박스의 연산이 끝나지 않아 저장되지 않았을 때 count의 값을 오른쪽 연산 박스가 읽어서 감소 연산을 한다면, 최종적으로 count에는 1만큼 감소된 값이 저장될 것이다. 이러한 문제는 특히 CPU가 여러 개가 있으면 생길 거라고 쉽게 추측할 수 있다.
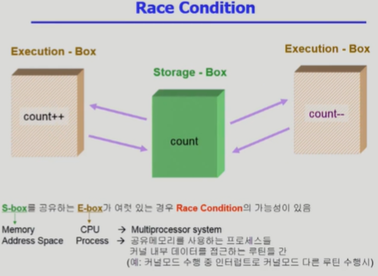
그렇다면 CPU가 하나인 상황에서는 어떠한가. 당연하게도(?) CPU가 하나라고 위의 문제가 발생하지 않는 것은 아니다. 그러나 반대로 하나라고 반드시 위의 문제가 발생하는 것도 아니다. (간장 공장 공장장) 사용자 프로세스는 본래 본인이 할당 받은 메모리 공간에만 접근이 가능하며 기본적으로 하나의 CPU는 프로세스 하나에 귀속되기 때문에 서로 다른 프로세스들 간의 주소 공간에 접근할 수 없다. 그럼 CPU가 한 개인 경우(싱글 코어) Race condition은 왜 생기는가?
문제는 바로 운영체제가 끼어드는 경우에 발생한다. A라는 프로세스가 실행 중이라고 하자. 프로세스는 본인이 할 수 없는 일을 운영체제에게 대신 해달라고 요청할 수 있다(시스템 콜). 그래서 이 시스템 콜을 통해 운영체제 안에 있는 어떤 데이터의 값을 바꾸고 있는 중이었다고 하자. 그때 A에게 주어진 타이머가 완료되어 다른 프로세스 B로 넘어갔다고 해보자. B도 본인이 할 수 없는 일을 하고 싶어 시스템콜을 했다고 해보자. 이때 A가 건드리던 데이터를 B도 건드리게 된다고 한다면, A가 건드리다가 말던 데이터가 B의 요청에 의해 바뀔 것이다. 그리고 나서 나중에 프로세스 A로 CPU가 다시 넘어가게 됐을 때 A가 하던 일을 다시 하게 되는데 이미 이 데이터를 읽어왔었기 때문에, 저장된 CPU의 문맥과 register들을 그대로 사용하게 되어 본래 의도와는 다른 결과가 나오게 될 수 있을 것이다.
요컨대 CPU가 여러 개 있거나, 설령 CPU가 하나만 있더라도 시스템콜을 통해 커널의 데이터를 건드리게 된다면 본래 의도와는 다른 결과가 초래될 수 있다. 이제 race condition이 발생하는 경우를 몇 가지 살펴보자.
1. Interrupt 발생 시 |
운영체제 코드가 수행 중이면서 이때 count를 1 증가시키려고 한다면 메모리 변수에서 레지스터로 값을 읽어 들이고, 그 값을 증가시키고 다시 메모리 변수에 저장시키는 작업을 해야 한다. 이때 첫 번째로 값을 load하고 두 번째로 증가시키려고 할 때, Interrupt가 들어왔다고 하자. 그러면 무조건 하던 일을 멈추고 인터럽트 처리 루틴으로 넘어 갈텐데 이때 처리 루틴이 count값을 감소시키려고 한다고 하자. 그러나 이 경우에도 인터럽트가 걸렸을 때의 저장된 문맥으로 돌아와서 count를 증가시키려고 하기 때문에 count 메모리 변수는 우리가 원하는 상쇄된 count값이 아니라 1만큼 증가된 count값이 될 것이다. 이 상황에서는 커널 모드를 통해 변수에 access 하기 전에 interrupt를 disable시키고 변수 작업이 끝나면 interrupt를 enable 시켜서 race condition을 해결할 수 있다.
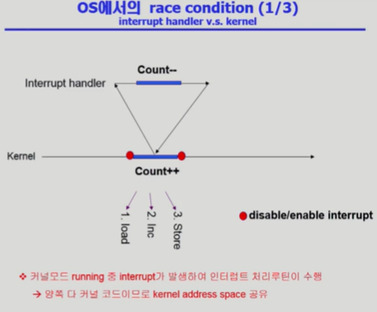
2. System call로 인한 race condition |
User mode로 프로세스 자신의 메모리 주소 공간에 접근할 때는 data sharing이 없으며 전혀 문제가 되지 않는다. 그러나 system call로 Kernel mode로 들어가 커널의 데이터를 건드리게 될 때, 커널 데이터는 일종의 공유 데이터이기 때문에 현재 프로세스 A뿐만 아니라 다른 프로세스 B도 건드릴 수 있게 된다.
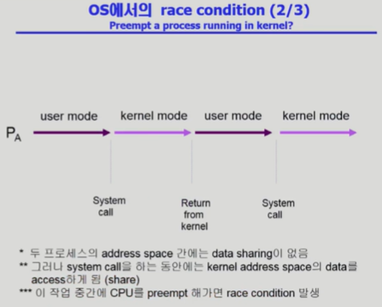
위의 예시에서 본래 의도로는 count를 두 번 증가시켜야 하지만 count가 한 번 증가된 상태로만 저장될 것이다. 즉, 커널 모드에서 CPU preempt가 문제를 발생시키는 것이기 때문에 timer가 끝났다고 하더라도 커널 모드에서 수행중인 프로세스에 대해서 CPU를 빼앗지 않게 하는 것이 해결책이 된다.
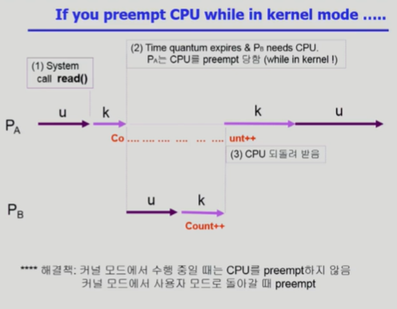
3. CPU가 여러 개일 때 발생하는 race condition |
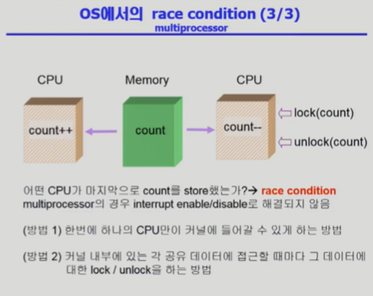
CPU가 여러 개일 때도 마찬가지로 운영체제가 개입했을 때 race condition이 발생한다. 이것은 interrupt가 있을 때 발생하는 race condition과는 전혀 다르다. Interrupt race condition은 CPU가 순차적으로 프로세스를 실행함에 있어 그 과정에서의 interrupt가 문제였다. 그러나 여기서는 단순히 해당 CPU interrupt handler를 disable했다고 해서 다른 CPU가 그 문제의 커널 데이터 부분에 access하지 않게 되는 것은 아니다.
따라서 이를 해결하기 위해, 어떤 CPU가 운영체제 커널 모드로 들어가게 된다면 다른 어떤 CPU도 운영체제 커널로 들어갈 수 없게 해야 한다. 어차피 여러 개의 CPU가 운영체제에 동시에 접근하며 발생하는 문제이기 때문에, 한 번에 한 개의 CPU만 운영체제를 점유하게 한다면 발생하지 않는 문제이다. 그러나 이 해결책은 굉장한 overhead가 뒤따르게 된다. 많은 CPU 중에 오직 하나만 운영체제에 들어갈 수 있게 된다면, 당연히 비효율적이 될 수밖에 없지 않은가!
그래서 위처럼 무식하게 운영체제 자체를 막아 버리는 것이 아니라 다른 해결책으로는 공유 데이터 각각을 lock / unlock하는 방법이 있다.

프로세스 동기화(Process Synchronization) |
지금까지는 운영체제에서 race condition의 문제를 다루었다. 물론 위와 같이 커널 모드에서 발생하는 경우 말고도, 이전 시간(언젠지 기억은 안남)에 배웠듯이 프로세스 간에 공유하는 메모리(Shared memory)를 둔다면 race condition이 발생할 수 있다. 따라서 shared memory를 쓴다면 Race condition의 문제가 발생하지 않도록 코딩을 해야 한다. 그것이 프로세스 동기화 (Process Synchronization)이다.
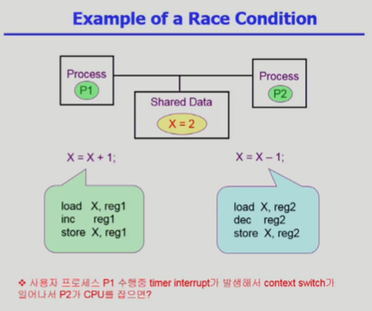
Process Synchronization 문제는 공유 데이터(shared data)의 동시 접근(concurrent access)으로 인해 데이터의 불일치(inconsistency)가 발생하는 것을 해결하기 위한 것이다. 이를 해결하고 일관성을 유지하기 위해서는 협력 프로세스들 간의 실행 순서를 정해주는 메커니즘이 필요하다. 즉, 이 문제는 프로세스 A가 실행하면서 공유 데이터를 접근하는 도중에 CPU를 빼앗아 다른 프로세스 B에게 넘기기 때문에 발생하는 문제이기 때문에 그것을 막는 무언가가 필요하다는 것이다.
다음 예시를 살펴보자. High language에서 X = X + 1; 과 같은 문장은 기계어로 좀 더 많은 문장으로 번역된다(Load, Inc, Store). 이때 P1에서 load X, reg1 부분에서 CPU를 P2에게 빼앗긴다면 문제가 발생하게 되는 것이다.
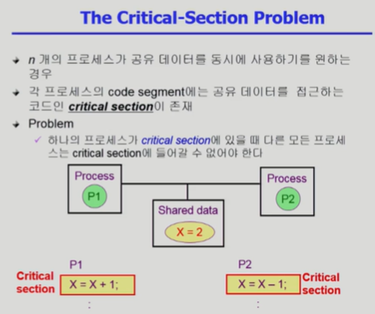
이처럼 여러 프로세스 간의 공유 데이터에 접근하여 사용하고자 하는 부분을 Critical-Section이라고 한다. 이 부분을 어떤 프로세스가 실행 중이면 해당 Section에 Lock을 걸어서, 설령 CPU를 빼앗기더라도 다른 프로세스가 해당 Critical-Section을 실행하지 못하도록 하는 것이 필요하다.

본 글들은 이화여대 반효경 교수님 2014학년도 1학기 운영체제 강의를 기반으로 작성됩니다.
링크 : http://www.kocw.net/home/search/kemView.do?kemId=1046323
'Operating System' 카테고리의 다른 글
| 7-3강. 동기화 문제(Deadlock) 해결 방안 (1) | 2020.02.13 |
|---|---|
| 7-2강. 동기화 문제 (0) | 2020.02.04 |
| 6-3강. CPU 스케줄링 알고리즘(Cont'd) (0) | 2020.01.29 |
| 6-2강. CPU 스케줄링 알고리즘 (1) | 2020.01.26 |
| 6-1강. CPU 스케줄링 (0) | 2020.01.24 |



